
Transcript Mapper
- Key tier combo box; the key tier is the tier used for lookups within the aligned types database. By default this is Orthography, but any grouped tier in the session may be used.
- Words/morphemes table; this table displayed the values for the word/morpheme alignment in the current record. The key tier will always be shown as the first column.
- Alignment options table; this table displayed data from the database which may be used to fill record data.
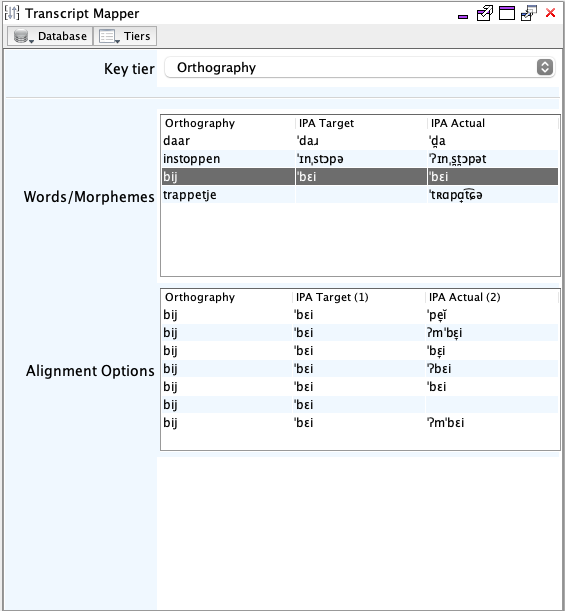
- Select the key tier from the provided combo box, this should be a tier in the record which contains data.
- Aligned words/morphemes in the current record will be listed in the
Word/morphemes table. Selecting a row in this table
will populate the Alignment options table with data
contained in the database for the selected word/morpheme in the indicated
key tier. Pressing enter (or right clicking) a row in the
Aligned words/morphemes table will display a menu with items to insert/update
alignment sets into the current record for all displayed tiers. If the selected
alignment set does not currently exist in the database an option to add the
alignment will also be presented.
Figure 2. Word/morpheme menu 
- The Alignment options table will display alignment sets
available in the database for the currently selected word/morpheme. Selecting a
row in this table and pressing enter (or right clicking) will display a menu
with items to insert//update specific tiers with types from the database (the
number keys 1-9 may also be used to select specific tiers.) Alignment sets may
be removed from the database by pressing delete or using the item in the popup menu.
Figure 3. Alignment options menu 
Aligned Types Database
The aligned types database is stored in the user's application data folder. This database folder is located at ~/Library/Application Support/Phon/transcriptMapper on macOS and %APPDATA%/Phon/transcriptMapper on Windows. The database filename is typeMap.atdz.
Database actions are available from the menu displayed when clicking the
Database button in the toolbar. Initially the
aligned types database is not populated. To import data into
the database, use one of the actions in the popup menu. When changes to the aligned
types databse are detected the Database button will be shown
with an asterisk '*' and a menu item to save the database will be
enabled.
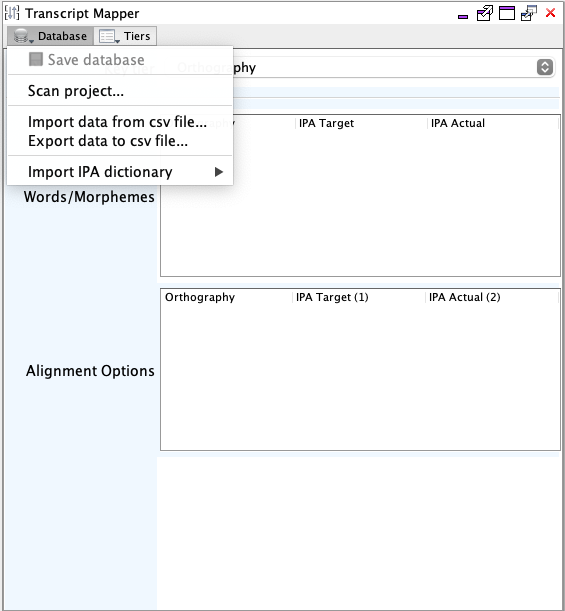
Save database
You may save the database using the appropriate menu item displayed in the database popup menu. The item is only enabled when changes have been detected.
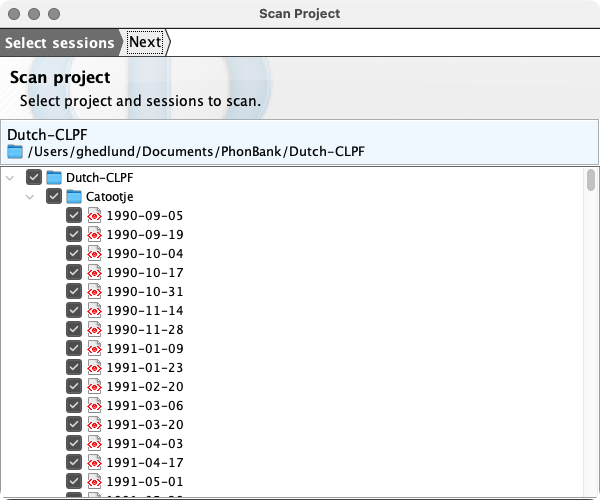
Scan Project
The scan project wizard allows for selection of session in the current project, or in another project, for data import to the database. Each aligned word/morpheme set - for all grouped tiers - in the scanned sessions will be added.
Import from CSV
Data may be imported from a CSV file. The first line of the CSV file should contain tier names, while each subsequent line should contain the aligned types to be added to the database. The CSV file should be UTF-8 encoded, with quotes around strings and commas separating values.
Export to CSV
Import IPA dictionary
Import Database
This feature is not yet available.
Project TypeMap Definitions
This feature is not yet available.
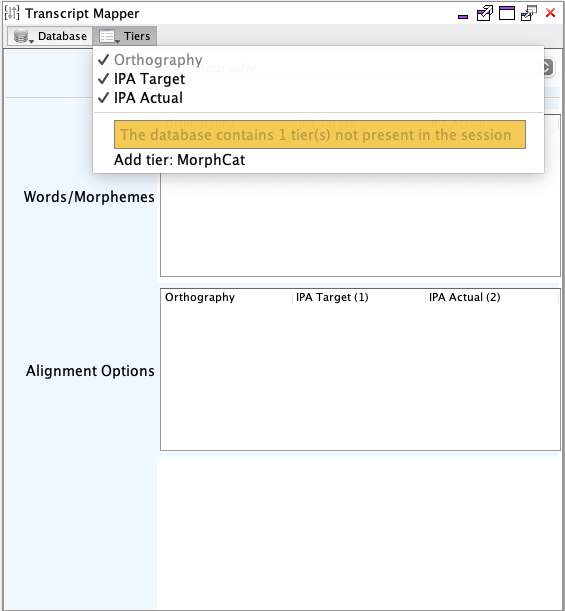
Tiers
Tiers displayed in transcript mapper tables may be controlled using the popup menu displayed when clicking the Tiers toolbar button. Initially all grouped tiers in the session are displayed in the order defined in the session with the exception that the current key tier will always be the first column. Only tiers displayed in the Words/morphemes table will be changed when selecting alignment data to insert.
It is possible that the database contains tiers which do not exist in the session. Missing tiers are displayed at the end of the Tiers menu with options to either add the missing tier to the session, or display the tier data in the Alignment options table.
Language Tier
- Import from CSV
During import from CSV the value for language is determined by (in order): column in the CSV file; language identified in Session Information; or default syllabifier language in application settings.
-
Scan Project
During scan project the value for language is determined by (in order): langauge identified in the first step of the Scan Project wizard; value from a tier named 'Language' in the session (must be grouped and aligned with each word/morpheme); language identified in Session Information; or default syllabifier language in application settings.
- Adding entries from Words/morphemes table
When adding alignment entries from the Words/morphemes table the value for language is determined by (in order): value from a tier named 'Language' in the session (must be grouped and aligned with each word/morpheme); language identified in Session Information; or default syllabifier language in application settings.